Can the Sentiment From YouTube Comments Resemble Audience Ratings?
 Image generated using Canva’s Text to Image AI generator
Image generated using Canva’s Text to Image AI generator
This is a repurposed analysis of a final project made for a graduate-level Data Science class.
PROJECT SUMMARY
- This project aims to analyze how audience ratings compare against the sentiment score of YouTube comments, using superhero movies and one content creator’s community as a point of reference.
- YouTube comments are only considered when they are within the top 50 most-voted and have a compound sentiment score of over .30 (on a -1 to 1 scale). Scores are then multiplied by 100 and redistributed to cover the full 0-100 range, resulting in 258 user comments.
- YouTube sentiment scores are mostly what is expected - i.e., positive movies tend to have higher sentiment scores - although there are a few notable exceptions.
- Audience ratings are highly correlated among themselves, whereas YouTube sentiments are moderately correlated to audience ratings - with the exception of YouTube and TMDb, which are highly correlated and have a statistically significant relationship.
- Even though YouTube sentiment scores were moderately correlated to audience ratings, there are several methodological limitations.
In an age before the internet, the entertainment industry would rely on traditional metrics - such as box office performance - and manual methods - such as audience surveys - to gather information on a show or film’s performance.
Then, in the early days of the internet, came along brands such as the Internet Movie Database (IMDb) or Rotten Tomatoes, which started aggregating reviews and granting scores for media creations.
But as the internet evolved, so did social media platforms such as Facebook. This meant being able to access more reviews at a quicker pace - but this information comes with the major caveat of being messy. Dealing with user-generated data makes it harder for people to understand what others are saying about a show or movie.
In this regard, this article explores how the sentiment score of YouTube comments compares against audience ratings, using superheros movies (along with their respective audience ratings and YouTube sentiments) as a point of reference.
The project is divided as follows:
- Methodology - what data is used and how is it preprocessed?
- Exploratory Analysis - how does the data look like?
- Statistical Analysis - are there relevant trends or relationships?
- Conclusions - what does it all mean and what are the next steps?
Methodology
This research process was iterative and nuanced - therefore, all data wrangling and analysis steps will be described in this upcoming section.
A graphic has been included to facilitate the explanation, but you can also refer to the expandable section below or the Jupyter Notebook (Python programming language script) if you’d like a deeper look into the methodology.

Click to read a deep dive into the methodology
What Data Is Used - Superhero Movies
This project will use several superhero movies as a point of comparison. This is done in order to use similar genres, therefore reducing the likelihood of results being due to chance alone.
Additionally, half of the movies in the sample were (arguably) positively received, while the other half were poorly rated (or, at the very least, got mixed reviews). The superhero movies compared are:
- Spider-Man: No Way Home (2021) - positive reception
- Logan (2017) - positive reception
- Thor: Ragnarok (2017) - positive reception
- Guardians of the Galaxy (2014) - positive reception
- Spider-Man 2 (2004) - positive reception
- Morbius (2022) - negative reception
- Dark Phoenix (2019) - negative reception
- Batman v Superman (2016) - negative reception
- Fantastic Four (2015) - negative reception
- Suicide Squad (2016) - negative reception
What Data Is Used - YouTube Reviews
This project will mainly rely on comments made on YouTube reviews, i.e., when a content creator talks about a movie or TV show and users react to it. All YouTube reviews are issued by the same content creator (Jeremy Jahns) in order to reduce randomness across the sample.
What Data Is Used - Audience Ratings
YouTube comments will be compared against multiple audience scores. Specifically, the audience scores employed are:
- Metacritic’s Metascore
- Rotten Tomatoes’ Tomatometer
- The Movie Database’s (TMDB’s) User Score
- The Internet Movie Database’s (IMDB’s) Rating
Each audience rating can slightly vary in its methodology. For example, the Metascore and Tomatometer have critic ratings while the TMDB and IMDB ratings are average viewers. All ratings can change over time as they receive more scores, but it is expected for them to stay relatively stable after a movie’s initial release.
How Data Is Downloaded and Preprocessed - Audience Scores
All data is downloaded and wrangled using the programming language Python.
The Movie Database’s (TMDB’s) Application Programming Interface (API) is used to access TMDB ratings, while the Open Movie Database’s (OMDB’s) API is used to access Rotten Tomatoes, IMDb, and Metacritic scores. Both sources allow users to generate API keys and download this data freely.
Additional wrangling is performed on each source so that each row corresponds to a different movie and each column contains their respective scores.
How Data Is Downloaded and Preprocessed - YouTube Comments
The library youtube-comment-downloader by Egbert Bouman is used to download YouTube comments along with the number of votes each receives and whether they are main comments or replies/threads.
From there, the data cleansing is a crucial step as the steps taken are meant to resemble how the author of this project would usually review comments: replies and threads are ignored and only the top 50 comments in terms of likes are taken into account.
The above-mentioned criteria emulates personal heuristics when assessing movie reviews. It is a method that has been of personal use and is arbitrary, so can, therefore, be further refined.
Lastly, all movies will have an IMDb ID and movie name - the ID will enable comparing YouTube comments against audience ratings in the next steps and the movie name is purely for readability purposes.
How Data Is Analyzed - YouTube Sentiments
The Valence Aware Dictionary and sEntiment Reasoner (VADER) model within the Natural Language Toolkit library (nltk) is used to create a sentiment score for each comment. The VADER model is a rule-based dictionary and is optimized for social media data.
The VADER model yields four types of sentiments - negative, neutral, positive, and compound (an aggregation of the previous three). This analysis relies on compound sentiments that are above .30 as the model is not sensitive to sarcasm and, therefore, tends to yield false negatives. Scores are then multiplied by 100 for better readability.
After applying the >.30 filter and multiplying scores by 100, they will follow some rules to be redistributed and cover the full 0-100 range: Scores below 61 will have 35 points deducted, scores between 61 and 64 will have 20 points deducted, scores between 64 and 68 will be left as is, and scores over 68 will have 15 points added.
It is also worth noting that the comments were not cleaned (e.g., emojis were not removed) and a few other sentiment analysis models (such as TextBlob) were explored.
How Data Is Analyzed - YouTube Sentiments Vs. Audience Ratings
Spearman correlation is used to analyze the data given that the audience ratings and YouTube sentiments do not tend to follow a normal distribution (rather, it tends to be bimodal). Additionally, it is expected that scores are monotonic rather than being tied, which is why Spearman correlation is preferred over Kendall’s tau.
Exploratory Analysis
Once the methodological nuances are out of the way, let’s dive into the actual data.
How Does The Data Look Like? - Raw YouTube Comments and Sentiments
The main data used for this analysis is a dataframe with 258 comments (rows) and 15 columns. This dataset comes after downloading the comments, running the sentiment analysis model, and filtering only for desired comments (top-voted and with a sentiment score of over .30).
Click on the expandable section below to read a description of the dataset, or click here to download the actual data.
Click to read a brief description of each column in the dataset
- cid: Unique identifier for each comment.
- text: The raw text or content of each comment.
- time: How long ago the comment was published (from the time of the data download).
- author: The username of the person who posted the comment.
- channel: The codified identifier for each username’s channel.
- votes: The number of upvotes each top-comment received.
- photo: A URL containing each user’s profile picture.
- heart: Whether the comment was liked by the YouTube content creator or not.
- reply: Whether the comment is part of a reply thread or not.
- time_parsed: Timestamp in which the data (YouTube comments) were scraped.
- video_url: The URL of the video that was scraped.
- sentiment_vader_all: A JSON structure with the negative, netural, positive, and compound sentiment scores.
- imdb_id: An identifier matching each comment to the movie they are referring to.
- movie_name: An identifier matching each comment to the movie they are referring to.
How Does The Data Look Like? - Average YouTube Sentiment Score
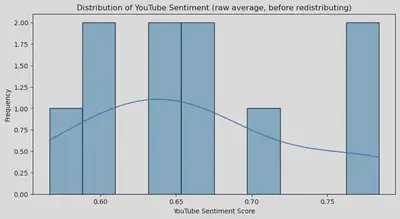
Once the raw comments have been analyzed and filtered, comes calculating the average sentiment score per movie (raw average before redistributing). Below is the result of said transformation.
| imdb_id | movie_name | sentiment_vader | |
|---|---|---|---|
| 0 | tt0316654 | Spider Man 2 2004 | 0.7730975 |
| 1 | tt10872600 | Spider Man No Way Home | 0.7044378378378379 |
| 2 | tt1386697 | Suicide Squad | 0.63852 |
| 3 | tt1502712 | Fantastic Four 2015 | 0.5890080000000001 |
| 4 | tt2015381 | Guardians of the Galaxy | 0.78428 |
| 5 | tt2975590 | Batman v Superman | 0.608745 |
| 6 | tt3315342 | Logan | 0.646065 |
| 7 | tt3501632 | Thor Ragnarok | 0.6582083333333334 |
| 8 | tt5108870 | Morbius | 0.6612878787878789 |
| 9 | tt6565702 | Dark Phoenix | 0.5661285714285714 |
The resulting scores oscilate between 0.6 and 0.8, despite scores being able to be as low as 0.3.
Setting aside that fact, the results are mostly what is expected, especially in terms of ranking - although there are some notable outliers.
For example, the Morbius (2022) movie was negatively received, yet scored above Logan, which is among the most praised superhero movies of all-time.
How Does The Data Look Like? - Redistributed YouTube Sentiments vs. Audience Ratings
Even though a correlation analysis can already be run based on ranking, the scores will be multiplied and redistributed to increase readability and cover the full 0-100 range.
As explained in the methodology section, the redistribution scoring logic goes as follows: Scores below 61 will have 35 points deducted, scores between 61 and 64 will have 20 points deducted, scores between 64 and 68 will be left as is, and scores over 68 will have 15 points added.
After redistributing YouTube sentiments - and comparing them against audience ratings - this is what we get.
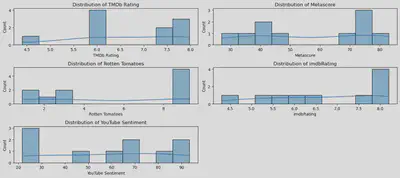

The redistributing of YouTube sentiments polarized the scores, making them be either low, mid, or high - and this trend more or less mirrors the audience rating’s distributions.
Metascore and Rotten Tomatoes are the ones with the most polarized scores, which is an interesting phenomena given that those two systems include more movie critics. TMDb and IMDb, on the other hand, are closer to an average viewer’s perspective, and this format allows for mid-level scores (which is also what happens with YouTube comments).
Statistical Analysis
At this point, we have already observed some interesting trends - but let’s see what a formal statistical analysis has to say on the matter.
As explained in the methodology section, Spearman correlation is an apt fit for this case given that the scores do not follow a strictly normal distribution. Additionally, it is unlikely for scores to be tied, which is why Spearman correlation is preferred over Kendall’s tau.
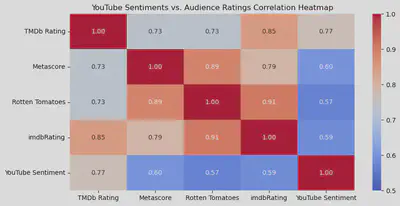
Below are the correlation coefficients and their associated p-values.
╒════╤══════════════════════════════════════╤═══════════════════════════╤═══════════╕
│ │ Rating Pair │ Correlation Coefficient │ P-Value │
╞════╪══════════════════════════════════════╪═══════════════════════════╪═══════════╡
│ 0 │ TMDb Rating vs Metascore │ 0.733333 │ 0.0158* │
├────┼──────────────────────────────────────┼───────────────────────────┼───────────┤
│ 1 │ TMDb Rating vs Rotten Tomatoes │ 0.731607 │ 0.0162* │
├────┼──────────────────────────────────────┼───────────────────────────┼───────────┤
│ 2 │ TMDb Rating vs imdbRating │ 0.854545 │ 0.0016** │
├────┼──────────────────────────────────────┼───────────────────────────┼───────────┤
│ 3 │ TMDb Rating vs YouTube Sentiment │ 0.769697 │ 0.0092** │
├────┼──────────────────────────────────────┼───────────────────────────┼───────────┤
│ 4 │ Metascore vs TMDb Rating │ 0.733333 │ 0.0158* │
├────┼──────────────────────────────────────┼───────────────────────────┼───────────┤
│ 5 │ Metascore vs Rotten Tomatoes │ 0.894187 │ 0.0005*** │
├────┼──────────────────────────────────────┼───────────────────────────┼───────────┤
│ 6 │ Metascore vs imdbRating │ 0.793939 │ 0.0061** │
├────┼──────────────────────────────────────┼───────────────────────────┼───────────┤
│ 7 │ Metascore vs YouTube Sentiment │ 0.6 │ 0.0667 │
├────┼──────────────────────────────────────┼───────────────────────────┼───────────┤
│ 8 │ Rotten Tomatoes vs TMDb Rating │ 0.731607 │ 0.0162* │
├────┼──────────────────────────────────────┼───────────────────────────┼───────────┤
│ 9 │ Rotten Tomatoes vs Metascore │ 0.894187 │ 0.0005*** │
├────┼──────────────────────────────────────┼───────────────────────────┼───────────┤
│ 10 │ Rotten Tomatoes vs imdbRating │ 0.906693 │ 0.0003*** │
├────┼──────────────────────────────────────┼───────────────────────────┼───────────┤
│ 11 │ Rotten Tomatoes vs YouTube Sentiment │ 0.569028 │ 0.0860 │
├────┼──────────────────────────────────────┼───────────────────────────┼───────────┤
│ 12 │ imdbRating vs TMDb Rating │ 0.854545 │ 0.0016** │
├────┼──────────────────────────────────────┼───────────────────────────┼───────────┤
│ 13 │ imdbRating vs Metascore │ 0.793939 │ 0.0061** │
├────┼──────────────────────────────────────┼───────────────────────────┼───────────┤
│ 14 │ imdbRating vs Rotten Tomatoes │ 0.906693 │ 0.0003*** │
├────┼──────────────────────────────────────┼───────────────────────────┼───────────┤
│ 15 │ imdbRating vs YouTube Sentiment │ 0.587879 │ 0.0739 │
├────┼──────────────────────────────────────┼───────────────────────────┼───────────┤
│ 16 │ YouTube Sentiment vs TMDb Rating │ 0.769697 │ 0.0092** │
├────┼──────────────────────────────────────┼───────────────────────────┼───────────┤
│ 17 │ YouTube Sentiment vs Metascore │ 0.6 │ 0.0667 │
├────┼──────────────────────────────────────┼───────────────────────────┼───────────┤
│ 18 │ YouTube Sentiment vs Rotten Tomatoes │ 0.569028 │ 0.0860 │
├────┼──────────────────────────────────────┼───────────────────────────┼───────────┤
│ 19 │ YouTube Sentiment vs imdbRating │ 0.587879 │ 0.0739 │
╘════╧══════════════════════════════════════╧═══════════════════════════╧═══════════╛
Starting with the audience scores, they are highly correlated among themselves. IMDb ratings seem to be the most representative as they have the highest correlation across all audience ratings, while the TMDb is the least correlated with other systems.
In terms of sentiment analysis, however, results are less desirable. All audience ratings are moderately-to-strongly correlated to the YouTube sentiment.
YouTube sentiments were most correlated to TMDb ratings, with this relationship being statistically significant.
Conclusions
It is comes as no surprise to say that analyzing social media sentiments is a tricky affair. There are many projects and datasets that attempt to do so, even focusing on movie reviews.
Despite the fact that YouTube sentiments came out as moderately-to-highly correlated, the results are not quite what was expected, which could be due to many reasons.
First, YouTube sentiments, by their nature, differ from audience ratings. Comments on YouTube do not solely focus on stating opinions about a movie - they can also engage with the content creator, reply to comments made on the video, or simply offer comedy relief.
Additionally, this project implemented several cleaning steps, such as including only those with a certain sentiment threshold, to attempt to include comments which would most resemble a review. However, these heurestics are arbitrary and did not yield ideal results.
Future works could explore several ideas to yield more desireable results. It may be worth exploring even more rule-based libraries or implementing alternative steps such as including positive sentiments instead of compound. It can also be worth implementing rules to detect sarcasm or even using a supervised machine learning model.
Miguel Curiel
Data | Insights | Growth
Bridging the gap between social science and data science. Passionate about people, insights, and stories.